把百万细胞预处理压到 5 GB:anndataoom 的级连惰性视图设计
单细胞图谱常常突破百万细胞,而标准分析栈会把整张表达矩阵读进内存,峰值 RAM 随细胞数线性增长,在普通工作站上很快耗尽。anndataoom 换了一种数据表示来绕开这堵墙:不把矩阵当成"每步都要重写的内存底物",而是把它当成一串可组合的磁盘视图来"看"。下面说明它的设计取舍,以及相对已有方案的差别。
| 单机跑完 | 峰值内存 | 同尺度省内存 | 百万细胞全流程 |
|---|---|---|---|
| 1,053,033 细胞 | ~5.0 GB(恒定) | ≈53× | 44.8 min |
问题:百万细胞撞上内存墙
主流的 AnnData 把细胞 × 基因矩阵以稠密或稀疏数组放在 RAM 里,预处理(质控、归一化、log、HVG、标准化、PCA)则不断地读取并重写这块内存矩阵。模型简单、速度快,但峰值内存随细胞数线性增长:一个 10⁶ 细胞 × 6×10⁴ 基因的稀疏计数矩阵就已经几十 GB,而 scale / Pearson 残差 / 回归这类稠密化变换会瞬时再撑大数十倍。
已有的 out-of-core 方案都只解决了一半:磁盘 backed 模式推迟加载,但一旦有变换碰数据就整块读进内存;通用分块框架(如 Dask)能流式跑单个算子,但标准预处理函数是按内存数组写的,照样 materialize。真正缺的,是让整条多步流水线——而不只是一步——端到端保持惰性、分块。
一个数据点:在 TS-Epi(228,032 细胞)上,稀疏原始矩阵在盘上只有约 11 GB,而 in-memory 峰值达到 107 GB。多出来的约 96 GB 是稠密中间产物,不是数据本身。
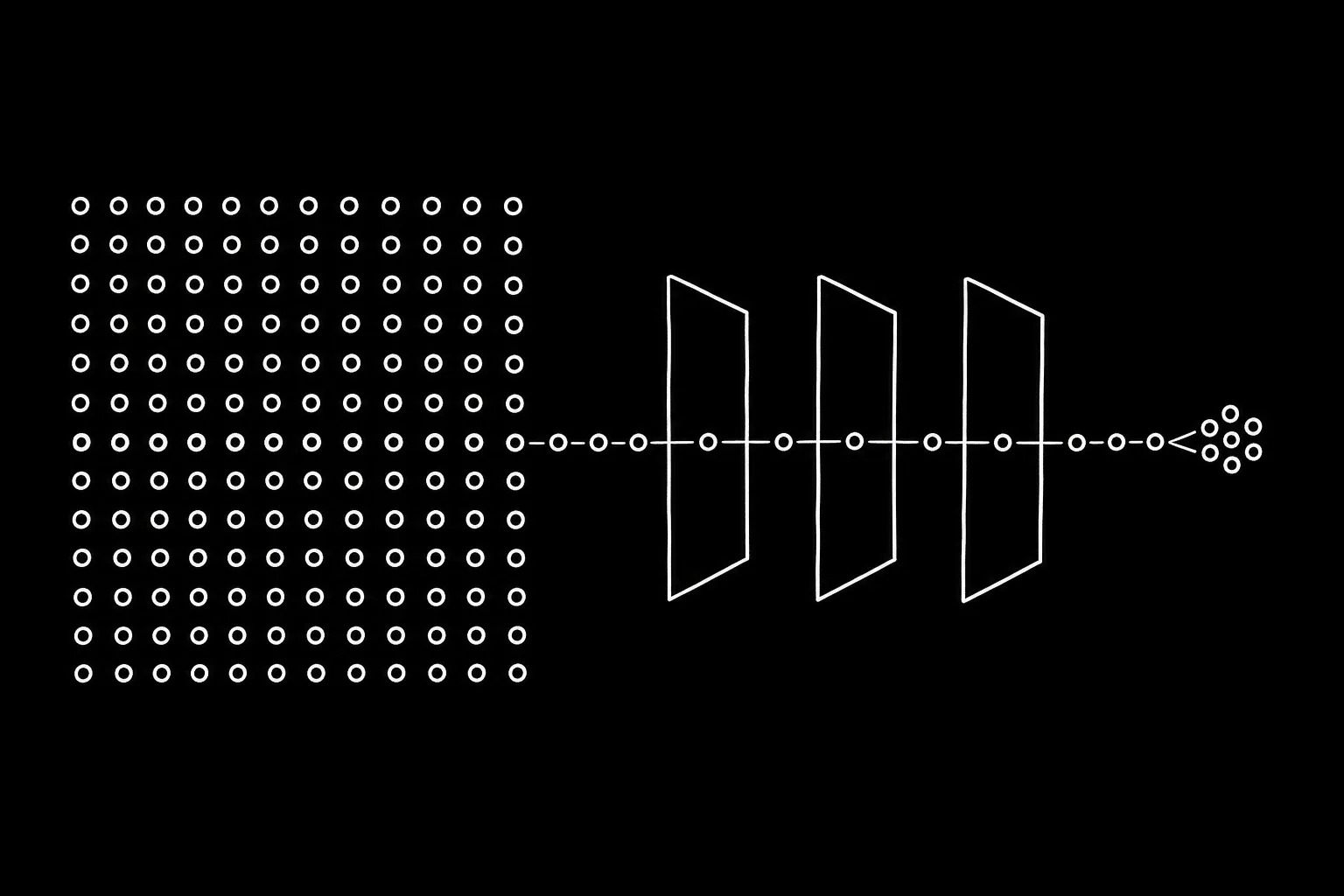
核心思路:不重写矩阵,而是"看"它
关键观察:单细胞预处理本质是一串"求值很贵、但描述极小"的局部映射的复合。归一化是每行除以一个标量;log1p 是逐元素;标准化是减每基因均值再除标准差;Pearson 残差是行和与列和的闭式函数;回归是减去一个小设计矩阵上的逐基因最小二乘。
没有一个需要"把整张矩阵放进内存"才能被描述——它们只需 O(细胞)+O(基因) 的小向量,而且都是局部的:某个元素的变换结果只依赖它自己和这些小参数。in-memory 设计无视了这个结构,把矩阵同时当作"存储"和"每步都要重写的计算底物",峰值就被矩阵本身绑死。
设计要点是:把"变换的描述"(极小、可组合)和"变换的求值"(按 chunk、读时现算)分开。每一步是一个包住父级的视图,读取时对 chunk 现算变换。N 步流水线因此合并成一次流式遍历,峰值内存等于一个 chunk,与细胞数无关。
那张稠密的"处理后矩阵"其实从头到尾都不存在(以完整形态):它只是中间废料。下游真正要的东西都很小——PCA 坐标 n_obs×50、HVG 标记、QC 指标。anndataoom 省掉的,恰恰是那个唯一随细胞数线性增长的东西。
级连的层级设计
矩阵被表示成一摞数组视图,每个视图暴露同样的极简接口(形状、分块行迭代器、行读取),要么从磁盘读字节,要么对父视图吐出的 chunk 做变换。高阶变换通过先调用父变换来组合(super()._transform_chunk)——子类层级就是变换的代数结构。一条真实的流水线视图链长这样:
X(HDF5 on disk, Rust I/O via anndata-rs)
→ TransformedBackedArray normalize:÷ 每细胞 size factor
→ TransformedBackedArray log1p:逐元素现算
→ _SubsetBackedArray HVG:选 2,000 个基因列(O(1))
→ ScaledBackedArray z-score:只存 mean/std 向量
→ Randomized SVD 分块矩阵乘
→ X_pca n_obs × 50,进内存
→ Neighbors / UMAP / Leiden 只在 X_pca 上跑
每层只存 O(细胞) 或 O(基因) 的小参数(2000 基因的 mean/std 约 16 KB),绝不写出完整的变换后矩阵:
| 视图层 | 包住谁 | 只存的状态 | 读时按 chunk 算什么 |
|---|---|---|---|
BackedArray | 磁盘(anndata-rs) | 形状、文件句柄 | 无——原始切片读 |
TransformedBackedArray | BackedArray | 每细胞除数;log 标记 | x / 因子;log1p(x) |
_SubsetBackedArray | 任意视图 | 行 / 列索引 | O(1) 子集(如选 2,000 个 HVG 列) |
ScaledBackedArray | Transformed | 每基因 mean、std;clip | (x − μ)/σ,裁剪 |
PearsonResidualBackedArray | Transformed | 行和、列和;θ、clip | (x − μ)/√(μ + μ²/θ) |
RegressedBackedArray | Transformed | betas (k×n_vars);设计阵 C | x − C·β |
三个实现细节
融合 + 链 re-basing:可交换的 normalize+log1p 融成一层;在已是 TransformedBackedArray 的视图上叠新变换时,会 re-base 到它的原始父级并把父参数前传。于是链深恒 ≤ 2,"加一步 = O(1) 开销"、"N 步塌缩成一遍"是字面成立的。
按语义保稀疏:视图知道"除法保零、log1p(0)=0",所以 normalize+log1p 仍吐稀疏 chunk;只有内在稠密的 scale/pearson/regress 才稠密化,且一次只稠密一个 chunk。
数值不退化:每步对原始数据现算,不在已 round 的 float32 中间结果上叠加;实测与 scanpy 位级吻合(normalize+log1p 2.4e-7、pearson 3.8e-6、regress 6e-7)。
为什么比之前的设计好
| 策略 | 峰值内存 | N 步读写 | 保稀疏 | 需重写函数 | 跑完 1M |
|---|---|---|---|---|---|
| in-memory(scanpy/ov) | O(细胞×基因)×2–3 | 读 1× | 仅 norm/log | 否 | 否 |
| backed 模式 | O(细胞×基因)(变换即 materialize) | 1× | 否 | 否 | 否 |
| 朴素 chunk 重写 | O(chunk) | ~2N× + N 份盘上中间文件 | 首次写即丢 | 是 | 是(I/O 受限) |
| 通用惰性数组(Dask/Zarr) | O(chunk) | ~1× | 看引擎 | 要移植全部函数 | 视情况 |
| 视图级连(anndataoom) | O(chunk) | 读 1×,无 scratch | norm/log 全程;其余 1 chunk 稠密 | 否(一行 dispatch) | 是 |
相对"最容易想到"的朴素分块重写:它也能做到 O(chunk),但代价是每步全量读+全量写(~2N× I/O)+ N 份磁盘临时文件,且一旦写出稠密中间结果就丢了稀疏。视图级连用"融合 + 只读一遍 + 不落地"把这些全省掉。而对 Dask/通用惰性数组:它不懂领域事实(log1p 保零、normalize 可交换、HVG 才需稠密化),还要把整套函数移植到新数组类型;视图级连是领域专用的,所以零重写、保稀疏。
性能:从 5k 到 100 万细胞
在 Tabula Sapiens 系列(5,000 → 1,053,033 细胞,均 60,606 基因)上、256 GB 内存上限下跑标准流水线。in-memory 与 scanpy-backed 的内存随细胞数线性增长,超过 ~23 万细胞即被 OOM kill;anndataoom 峰值基本恒定(0.9 → 5.2 GB),是唯一跑完百万细胞的配置。
恒定内存并没有牺牲速度:超过最小数据集后,anndataoom 与 in-memory 处于同一时间带,在 TS-Epi 上甚至更快(800.7 s vs 880.1 s);百万细胞全流程 44.8 min(2,688.7 s)。只有在 TS-5k 这种"稠密都轻松放得下"的小数据上,分块迭代的固定开销才显出来——而那种场景本就不需要 out-of-core。
CPU 与 CPU–GPU 混合后端在时间上基本不敏感(TS-1M:2,811 s vs 2,689 s,同 ~5 GB)——out-of-core 流水线大多受 I/O 与分块调度限制,而非纯算力。
一套算子,两种 backing store
这个思路其实也能让 in-memory 更瘦:视图的底层只是个"能吐 chunk 的 array-like",所以同一套 chunked 算子 + 隐式中心化 PCA 对"矩阵在盘上还是在 RAM"是无关的。套到内存稀疏矩阵上,就能干掉 in-memory 的主要爆点——scale/pearson/PCA 的瞬时稠密副本——而不改变原始稀疏的 O(nnz) 占用。
我们的隐式中心化配置正是这个思路用在 PCA 上:TS-Epi 峰值从 ~107 GB 砍到 ~48 GB,还跑通了 dense PCA 跑不动的 592k。但我们刻意止步于此——不把整个 in-memory 矩阵惰性化:anndataoom 已覆盖"放不下"的场景,"放得下"时 eager 稠密核更快,且全面惰性化会破坏生态对 concrete-array 的假设、拖慢快路径。一句话定位:一套算子、两种 backing store(RAM 求更瘦的 in-memory,disk 求恒内存 out-of-core)。
上手:三行读入,全程惰性
pip install anndataoom预编译 wheel 内置静态 HDF5,无需系统依赖、无需 Rust 工具链(Linux x86_64 / macOS arm64·x86_64 / Windows x86_64(0.1.8+),Python 3.10–3.12)。用法对用户透明:用 anndataoom 读数据,然后照常调 ov.pp.*,整条 qc → 预处理 → HVG 子集 → scale → PCA → 邻居/UMAP/Leiden 全程 out-of-core,无需改一行调用代码;ov.pl.* 画图(含 use_raw=True)也照常可用。
import anndataoom as oom, omicverse as ov
adata = oom.read("atlas_1M.h5ad") # 矩阵留在磁盘,X 是惰性 BackedArray
ov.pp.qc(adata, doublets=False) # 质控:一次 chunked 扫描,只写 obs/var
ov.pp.preprocess(adata, mode="shiftlog|pearson", n_HVGs=2000)
adata.raw = adata
adata = adata[:, adata.var.highly_variable_features] # O(1) 惰性列子集
ov.pp.scale(adata) # 惰性 z-score(只存 mean/std 向量)
ov.pp.pca(adata, layer="scaled", n_pcs=50) # chunked randomized SVD
ov.pp.neighbors(adata, n_pcs=50); ov.pp.umap(adata); ov.pp.leiden(adata)
ov.pl.embedding(adata, basis="X_umap", color="leiden") # 全程峰值 ≈ 一个 chunk标准预处理面基本全覆盖:qc、normalize_total、log1p、highly_variable_genes、scale、pca、filter_cells/genes、normalize_pearson_residuals、regress 都走 OOM 路径;scrublet 走"只 materialize HVG 子集"的有界路径。不支持的子情形会在调用处直接抛清晰异常,绝不静默算错。
局限与注意
- PCA 精度:默认在 HVG 子矩阵上做一次内存内 randomized SVD(sklearn),对单细胞常用的前 50 个主成分与标准 PCA 高度一致(单细胞谱衰减快,实测 |cos| = 1.0);只有谱衰减很慢的合成/强批次数据才需调高幂迭代次数。
- 写回 X 是惰性的:
adata[mask] = value会触发 materialize;要持久化改动请用adata.write(path)(分块写,不 materialize)或改obs/obsm。 - 少数本质全局的算子(某些非 Harmony 批次校正等)仍需 materialize,会带告警执行。
- 文件锁:默认
backed='r'只读、保护源文件;HDF5 默认独占锁,多进程读同一文件需设HDF5_USE_FILE_LOCKING=FALSE。
结语
选对数据表示后,百万细胞级的单细胞预处理可以做到内存恒定:把流水线表示成一串可组合的磁盘视图,合并成一次惰性遍历,在数学允许处保留稀疏,并以不变的 API 名字对外暴露。换句话说,内存恒定是这种表示本身的性质,而不是事后叠加的优化——原本看起来是内存工程问题,选对表示后它变成了一个数据表示问题。
底层建立在 scverse/anndata-rs(AnnData 的 Rust 实现,© Kai Zhang)之上,pin 到固定 commit 以保证可复现(与 SnapATAC2 同源)。MIT 协议。
@software{anndataoom,
title = {anndata-oom: out-of-memory AnnData for constant-memory
single-cell preprocessing},
author = {Zeng, Zehua and {the anndata-oom contributors}},
url = {https://github.com/omicverse/anndata-oom},
year = {2026},
}